sparklyr is a new R front-end for Apache Spark, developed by the good people at RStudio. It offers much more functionality compared to the existing SparkR interface by Databricks, allowing both dplyr-based data transformations, as well as access to the machine learning libraries of both Spark and H2O Sparkling Water. Moreover, the latest RStudio IDE v1.0 now offers native support for managing Spark connections and viewing Spark context data in a dedicated tab.
Although there are already lots of examples provided by RStudio, rather unsurprisingly almost all of them focus on using Spark in local mode (the billion NYC taxi trips analysis is an exception, but we’ll see later where it falls short as an example). So, I thought of getting the new package for a test drive on YARN, and here are my preliminary findings, hints, and tips.
In what follows, we use sparklyr version 0.4, i.e. the latest stable version available in CRAN at the time of writing.
RStudio Server required
If you expected to be able to connect to a remote cluster from your RStudio Desktop, you’d better forget it, at least for the time being; here is the message you get when attempt to connect to a remote cluster:
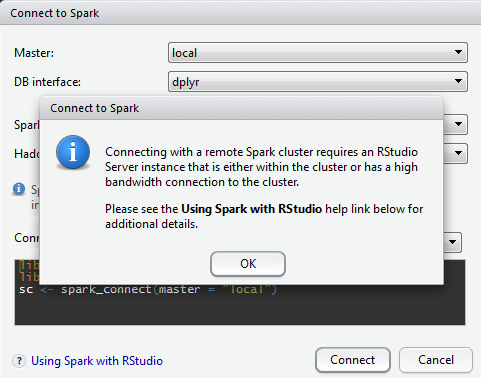
RStudio Desktop message when attempting to connect to a remote cluster
This means that, even if your machine is directly connected to the cluster, you still cannot use the connection functionality provided by RStudio Desktop.
That said, truth is that in what follows I found little use of this functionality even with RStudio Server, ending up managing the connection in-script – and I cannot imagine that one cannot do the same from RStudio Desktop, provided that the machine has direct access to the cluster (not tested though).
Configuring your resources
When working in local mode, you don’t actually have to specifically define the resources to be used; but when working on YARN, this is necessary. Here is the configuration used in the billion NYC taxi trips analysis example mentioned above:
config <- spark_config() config$spark.driver.cores <- 32 config$spark.executor.cores <- 32 config$spark.executor.memory <- "40g"
That’s great, only I want to also specify a number of executors. Of course, I cannot remember by heart all the different configuration arguments – what’s the documentation for? So, I went through the Spark 1.6.1 configuration documents, looking for the exact argument to use.
But it’s not there… Neither it is in the relevant Spark 2.0.0 docs. I can find how to configure memory and cores for both driver and executors, along with dozens of other things, but nothing about the number of executors…
I finally located it in some old Spark 1.5 documents – it is spark.executor.instances, with a default value of 2; it is a mystery to me why they chose not to include it in later versions of the documentation – but again, I have already argued elsewhere about puzzling and missing things in Spark docs.
With this last piece, we are now ready to setup a Spark connection to YARN via sparklyr from an RStudio Server instance within our cluster:
library(sparklyr) Sys.setenv(SPARK_HOME = "/home/ctsats/spark-1.6.1-bin-hadoop2.6") Sys.setenv(HADOOP_CONF_DIR = '/etc/hadoop/conf.cloudera.hdfs') Sys.setenv(YARN_CONF_DIR = '/etc/hadoop/conf.cloudera.yarn') config <- spark_config() config$spark.executor.instances <- 4 config$spark.executor.cores <- 4 config$spark.executor.memory <- "4G" sc <- spark_connect(master="yarn-client", config=config, version = '1.6.1')
And, I am happy to report, it works like a charm.
It is advisable that the definitions of the relevant environmental variables be included in the Renviron.site configuration file; while this sounds like a good idea for HADOOP_CONF_DIR and YARN_CONF_DIR, I prefer to have a more explicit and dynamic control of SPARK_HOME, since I maintain several different Spark versions in my cluster.
dplyr is required
Let’s try some elementary operations from the examples first; the following command should upload the iris data to our Spark context:
> iris_tbl <- copy_to(sc, iris, "iris", overwrite = TRUE) Error: could not find function "copy_to"
This error puzzled me, and it took some time to figure it out; after all, copy_to is indeed a sparklyr function.
It turns out that some sparklyr functions, including copy_to, require dplyr in order to be available:
> library(dplyr)
> iris_tbl <- copy_to(sc, iris, "iris", overwrite = TRUE)
The following columns have been renamed:
- 'Sepal.Length' => 'Sepal_Length' (#1)
- 'Sepal.Width' => 'Sepal_Width' (#2)
- 'Petal.Length' => 'Petal_Length' (#3)
- 'Petal.Width' => 'Petal_Width' (#4)
> iris_tbl
Source: query [?? x 5]
Database: spark connection master=yarn-client app=sparklyr local=FALSE
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
<dbl> <dbl> <dbl> <dbl> <chr>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# ... with more rows
Although not explicitly mentioned, this (i.e. loading both sparklyr and dplyr) is the advised usage, as implied by the suggested connection code popping up in the Spark tab of RStudio:
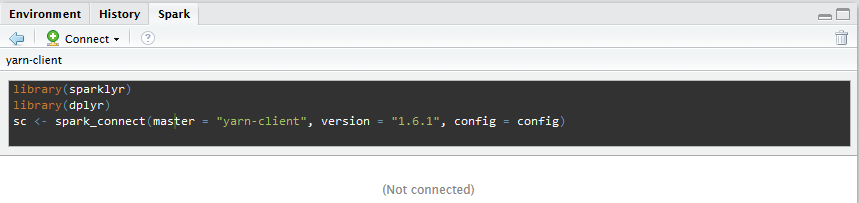
Connection code snippet
Replicating the machine learning examples with Titanic data
There is a nice example by RStudio, comparing six Spark ML algorithms on the Titanic data. It is not entirely reproducible though, due to an enigmatic line:
spark_read_parquet(sc, name = "titanic", path = "titanic-parquet")
which loads the Titanic data from an external Parquet file.
Trying to directly use the Titanic data as provided by the titanic R package produces an error in YARN mode:
> library(titanic) > titanic_tbl <- copy_to(sc, titanic::titanic_train, "titanic", overwrite = TRUE) Error: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 2.0 failed 4 times, most recent failure: Lost task 0.3 in stage 2.0 (TID 5, host-hd-03.corp.nodalpoint.com): java.lang.ArrayIndexOutOfBoundsException: 11 [...]
while, curiously enough, in local mode the command works OK (I have opened an issue at Github).
Fortunately, saving the Titanic data in a local CSV file and then reading them from there works OK:
> write.csv(titanic_train, file="/home/ctsats/R/titanic.csv", row.names=FALSE)
> library(readr)
> titanic <- read_csv("~/R/titanic.csv") [...]
> titanic_tbl <- copy_to(sc, titanic, "titanic", overwrite = TRUE)
> titanic_tbl
Source: query [?? x 12]
Database: spark connection master=yarn-client app=sparklyr local=FALSE
PassengerId Survived Pclass Name Sex Age SibSp Parch
<int> <int> <int> <chr> <chr> <dbl> <int> <int>
1 1 0 3 Braund, Mr. Owen Harris male 22 1 0
2 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 3 1 3 Heikkinen, Miss. Laina female 26 0 0
4 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 5 0 3 Allen, Mr. William Henry male 35 0 0
6 6 0 3 Moran, Mr. James male NaN 0 0
7 7 0 1 McCarthy, Mr. Timothy J male 54 0 0
8 8 0 3 Palsson, Master. Gosta Leonard male 2 3 1
9 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27 0 2
10 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14 1 0
# ... with more rows, and 4 more variables: Ticket <chr>, Fare <dbl>, Cabin <chr>, Embarked <chr>
File access and paths
You can use spark_read_csv to access local files, but only in local mode – it will not work in YARN client mode:
> spark_disconnect(sc) # disconnect from YARN
> sc <- spark_connect(master = "local", version = '1.6.1') # connect in local mode
> spark_read_csv(sc, name="titanic_local", path="file:///home/ctsats/R/titanic.csv", header=TRUE) # local file
Source: query [?? x 12]
Database: spark connection master=local[12] app=sparklyr local=TRUE
PassengerId Survived Pclass Name Sex Age SibSp Parch
<int> <int> <int> <chr> <chr> <chr> <int> <int>
1 1 0 3 Braund, Mr. Owen Harris male 22 1 0
2 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 3 1 3 Heikkinen, Miss. Laina female 26 0 0
4 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 5 0 3 Allen, Mr. William Henry male 35 0 0
6 6 0 3 Moran, Mr. James male NA 0 0
7 7 0 1 McCarthy, Mr. Timothy J male 54 0 0
8 8 0 3 Palsson, Master. Gosta Leonard male 2 3 1
9 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27 0 2
10 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14 1 0
# ... with more rows, and 4 more variables: Ticket <chr>, Fare <dbl>, Cabin <chr>, Embarked <chr>
> spark_disconnect(sc) # disconnect from local
> sc <- spark_connect(master="yarn-client", config=config, version = '1.6.1') # reconnect to YARN
> spark_read_csv(sc, name="titanic_local", path="file:///home/ctsats/R/titanic.csv", header=TRUE) # same local file
Error: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 4 times, most recent failure: Lost task 0.3 in stage 1.0 (TID 4, host-hd-03.corp.nodalpoint.com): java.io.FileNotFoundException: File file:/home/ctsats/R/titanic.csv does not exist
[...]
By default, the path argument in spark_read_csv refers to the HDFS path; so, after having copied titanic.csv to HDFS directory sparklyr, we can read it like this:
> spark_read_csv(sc, name="titanic_hdfs", path="sparklyr/titanic.csv", header=TRUE) # HDFS file
Source: query [?? x 12]
Database: spark connection master=local[12] app=sparklyr local=TRUE
PassengerId Survived Pclass Name Sex Age SibSp Parch
<int> <int> <int> <chr> <chr> <chr> <int> <int>
1 1 0 3 Braund, Mr. Owen Harris male 22 1 0
2 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 3 1 3 Heikkinen, Miss. Laina female 26 0 0
4 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 5 0 3 Allen, Mr. William Henry male 35 0 0
6 6 0 3 Moran, Mr. James male NA 0 0
7 7 0 1 McCarthy, Mr. Timothy J male 54 0 0
8 8 0 3 Palsson, Master. Gosta Leonard male 2 3 1
9 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27 0 2
10 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14 1 0
# ... with more rows, and 4 more variables: Ticket <chr>, Fare <dbl>, Cabin <chr>, Embarked <chr>
Nevertheless, while experimenting, I found one occasion where this simple path reference will not work, demanding a reference to the full HDFS path preceded with hdfs://:
> spark_read_csv(sc, name="interactions", path="recsys/data/interactions_clean.csv", header=TRUE) # HDFS file
Error: org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://host-hd-01.corp.nodalpoint.com:8020/home/ctsats/recsys/data/interactions_clean.csv
[...]
> spark_read_csv(sc, name="interactions", path="hdfs:///user/ctsats/recsys/data/interactions_clean.csv", header=TRUE) # full HDFS path provided
Source: query [?? x 3]
Database: spark connection master=local[12] app=sparklyr local=TRUE
user_id item_id interaction_type
<int> <int> <int>
1 7 1006839 1
2 9 944146 3
3 9 1053485 1
4 13 2444782 1
5 23 501722 1
6 23 1305844 1
7 28 252140 1
8 28 931378 1
9 28 1038508 1
10 28 1083127 1
# ... with more rows
This is rather strange, as the error message suggests that Spark is looking for the file in the path hdfs:///home/ctsats/recsys/data/interactions_clean.csv, instead of the correct one hdfs:///user/ctsats/recsys/data/interactions_clean.csv. Although I could not reproduce this behavior with other files, it is maybe a good idea to include the full HDFS paths for your file references, just to be on the safe side.
Summary
To summarize, here are our first impressions and hints for using sparklyr on YARN:
- The RStudio built-in functionality for managing remote Spark connections is only available for the server and not for the desktop IDE, although this functionality is not of much use
- dplyr is required along, even for functions that appear to be native to sparklyr
- You cannot access local files
- There may be cases where you need to specify the full HDFS path for accessing files stored in Hadoop

- Streaming data from Raspberry Pi to Oracle NoSQL via Node-RED - February 13, 2017
- Dynamically switch Keras backend in Jupyter notebooks - January 10, 2017
- sparklyr: a test drive on YARN - November 7, 2016
[…] article was first published on R – Nodalpoint, and kindly contributed to […]
I have also described YARN cluster attempt 2 months ago in my blog post Extending sparklyr to Compute Cost for K-means on YARN Cluster with Spark ML Library
http://r-bloggers.com/extending-sparklyr-to-compute-cost-for-k-means-on-yarn-cluster-with-spark-ml-library/