In our previous post, we demonstrated how to setup the necessary software components, so that we can develop and deploy Spark applications with Scala, Eclipse, and sbt. We also included the example of a simple application.
In this post, we are taking this demonstration one step further. We discuss a more serious application of a recommender system and present the new sbt configuration to reflect:
- Dependencies on Spark libraries (MLlib)
- Dependencies on external Scala libraries (scopt command line parser)
Create the new project
This time we will create an empty project and use Eclipse IDE to manage it.
~$ mkdir RecommendationApp ~$ cd RecommendationApp/ ~/RecommendationApp$ mkdir -p src/main/scala ~/RecommendationApp$ find . . ./src ./src/main ./src/main/scala
In the directory ~/RecommendationApp, create the sbt configuration file named recommendation.sbt as follows:
name := "Recommendation-Project" version := "1.0" scalaVersion := "2.11.7" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.4.1" % "provided"
Notice the keyword provided at the end of the library dependencies line. We will come to this later.
~/RecommendationApp$ sbt eclipse
[info] Loading global plugins from /home/osboxes/.sbt/0.13/plugins
[info] Set current project to recommendationapp (in build file:/home/osboxes/RecommendationApp/)
[info] About to create Eclipse project files for your project(s).
[info] Updating {file:/home/osboxes/RecommendationApp/}recommendationapp...
[info] Resolving org.fusesource.jansi#jansi;1.4 ...
[info] Done updating.
[info] Successfully created Eclipse project files for project(s):
[info] recommendationapp
~/RecommendationApp$
We can now import the empty project into Eclipse:
Now add a new Scala object.
Enter the name of the object as MovieLensALS. A new Scala source file will be created. Please copy & paste the following code, which is also included in the Spark MLlib examples directory of every Spark installation:
import scala.reflect.runtime.universe._
import scala.collection.mutable
import org.apache.log4j.{Level, Logger}
import scopt.OptionParser
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
/**
* An example app for ALS on MovieLens data (http://grouplens.org/datasets/movielens/).
* A synthetic dataset in MovieLens format can be found at `data/mllib/sample_movielens_data.txt`.
* If you use it as a template to create your own app, please use `spark-submit` to submit your app.
*/
object MovieLensALS {
case class Params(
input: String = null,
kryo: Boolean = false,
numIterations: Int = 20,
lambda: Double = 1.0,
rank: Int = 10,
numUserBlocks: Int = -1,
numProductBlocks: Int = -1,
implicitPrefs: Boolean = false) extends AbstractParams[Params]
def main(args: Array[String]) {
val defaultParams = Params()
val parser = new OptionParser[Params]("MovieLensALS") {
head("MovieLensALS: an example app for ALS on MovieLens data.")
opt[Int]("rank")
.text(s"rank, default: ${defaultParams.rank}}")
.action((x, c) => c.copy(rank = x))
opt[Int]("numIterations")
.text(s"number of iterations, default: ${defaultParams.numIterations}")
.action((x, c) => c.copy(numIterations = x))
opt[Double]("lambda")
.text(s"lambda (smoothing constant), default: ${defaultParams.lambda}")
.action((x, c) => c.copy(lambda = x))
opt[Unit]("kryo")
.text("use Kryo serialization")
.action((_, c) => c.copy(kryo = true))
opt[Int]("numUserBlocks")
.text(s"number of user blocks, default: ${defaultParams.numUserBlocks} (auto)")
.action((x, c) => c.copy(numUserBlocks = x))
opt[Int]("numProductBlocks")
.text(s"number of product blocks, default: ${defaultParams.numProductBlocks} (auto)")
.action((x, c) => c.copy(numProductBlocks = x))
opt[Unit]("implicitPrefs")
.text("use implicit preference")
.action((_, c) => c.copy(implicitPrefs = true))
arg[String]("<input>")
.required()
.text("input paths to a MovieLens dataset of ratings")
.action((x, c) => c.copy(input = x))
note(
"""
|For example, the following command runs this app on a synthetic dataset:
|
| bin/spark-submit --class org.apache.spark.examples.mllib.MovieLensALS \
| examples/target/scala-*/spark-examples-*.jar \
| --rank 5 --numIterations 20 --lambda 1.0 --kryo \
| data/mllib/sample_movielens_data.txt
""".stripMargin)
}
parser.parse(args, defaultParams).map { params =>
run(params)
} getOrElse {
System.exit(1)
}
}
def run(params: Params) {
val conf = new SparkConf().setAppName(s"MovieLensALS with $params")
//.setMaster("local[2]")
if (params.kryo) {
conf.registerKryoClasses(Array(classOf[mutable.BitSet], classOf[Rating]))
.set("spark.kryoserializer.buffer", "8m")
}
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
val implicitPrefs = params.implicitPrefs
val ratings = sc.textFile(params.input).map { line =>
val fields = line.split("::")
if (implicitPrefs) {
/*
* MovieLens ratings are on a scale of 1-5:
* 5: Must see
* 4: Will enjoy
* 3: It's okay
* 2: Fairly bad
* 1: Awful
* So we should not recommend a movie if the predicted rating is less than 3.
* To map ratings to confidence scores, we use
* 5 -> 2.5, 4 -> 1.5, 3 -> 0.5, 2 -> -0.5, 1 -> -1.5. This mappings means unobserved
* entries are generally between It's okay and Fairly bad.
* The semantics of 0 in this expanded world of non-positive weights
* are "the same as never having interacted at all".
*/
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)
} else {
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}
}.cache()
val numRatings = ratings.count()
val numUsers = ratings.map(_.user).distinct().count()
val numMovies = ratings.map(_.product).distinct().count()
println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")
val splits = ratings.randomSplit(Array(0.8, 0.2), 1)
val training = splits(0).cache()
val test = if (params.implicitPrefs) {
/*
* 0 means "don't know" and positive values mean "confident that the prediction should be 1".
* Negative values means "confident that the prediction should be 0".
* We have in this case used some kind of weighted RMSE. The weight is the absolute value of
* the confidence. The error is the difference between prediction and either 1 or 0,
* depending on whether r is positive or negative.
*/
splits(1).map(x => Rating(x.user, x.product, if (x.rating > 0) 1.0 else 0.0))
} else {
splits(1)
}.cache()
val numTraining = training.count()
val numTest = test.count()
println(s"Training: $numTraining, test: $numTest.")
ratings.unpersist(blocking = false)
val model = new ALS()
.setRank(params.rank)
.setIterations(params.numIterations)
.setLambda(params.lambda)
.setImplicitPrefs(params.implicitPrefs)
.setUserBlocks(params.numUserBlocks)
.setProductBlocks(params.numProductBlocks)
.run(training)
val rmse = computeRmse(model, test, params.implicitPrefs)
println(s"Test RMSE = $rmse.")
sc.stop()
}
/** Compute RMSE (Root Mean Squared Error). */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], implicitPrefs: Boolean)
: Double = {
def mapPredictedRating(r: Double): Double = {
if (implicitPrefs) math.max(math.min(r, 1.0), 0.0) else r
}
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map{ x =>
((x.user, x.product), mapPredictedRating(x.rating))
}.join(data.map(x => ((x.user, x.product), x.rating))).values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).mean())
}
}
/**
* Abstract class for parameter case classes.
* This overrides the [[toString]] method to print all case class fields by name and value.
* @tparam T Concrete parameter class.
*/
abstract class AbstractParams[T: TypeTag] {
private def tag: TypeTag[T] = typeTag[T]
/**
* Finds all case class fields in concrete class instance, and outputs them in JSON-style format:
* {
* [field name]:\t[field value]\n
* [field name]:\t[field value]\n
* ...
* }
*/
override def toString: String = {
val tpe = tag.tpe
val allAccessors = tpe.declarations.collect {
case m: MethodSymbol if m.isCaseAccessor => m
}
val mirror = runtimeMirror(getClass.getClassLoader)
val instanceMirror = mirror.reflect(this)
allAccessors.map { f =>
val paramName = f.name.toString
val fieldMirror = instanceMirror.reflectField(f)
val paramValue = fieldMirror.get
s" $paramName:\t$paramValue"
}.mkString("{\n", ",\n", "\n}")
}
}
The above code defines a Scala object MovieLensALS, containing the main entry of the application, and a helper class AbstractParams that finds all case class fields in a concrete class instance and outputs them in JSON-style format. Normally, this helper class would be located in its own source file; for this example, we merged the definitions of MovieLensALS and AbstractParams into one single file.
Eclipse immediately tries to resolve all dependencies and highlights all the missing ones:
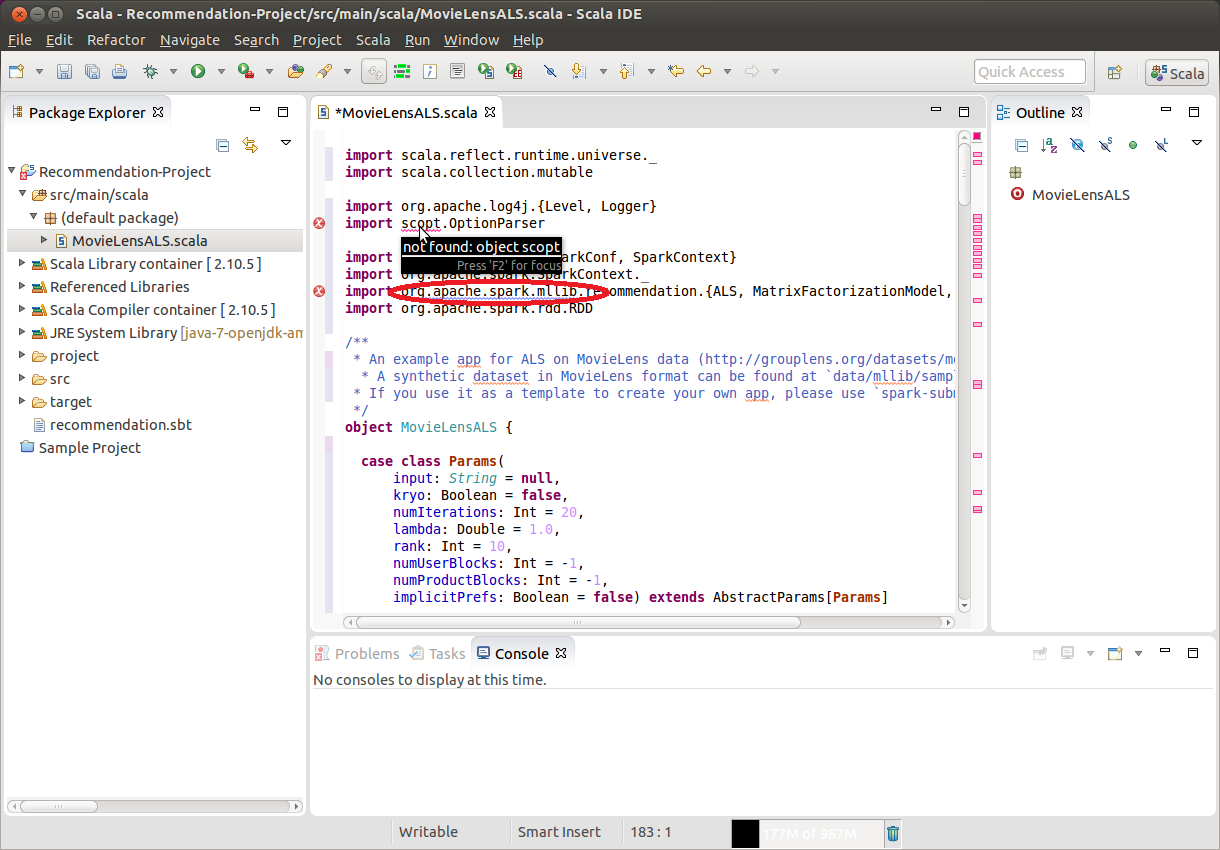
From the figure above we can see two libraries missing: (a) spark/mllib and (b) scopt for command line argument parsing. The first one is an essential part of all Spark distributions, while the second one is an external dependency.
There are many ways to overcome the problems of missing dependencies (jars) in Eclipse IDE; in this post, we will use the sbt tool to create them, since it is also used for code packaging. This way we accomplish a uniform development/deployment environment.
We need to edit the ~/RecommendationApp/recommendation.sbt and add two further depedencies, as shown below:
name := "Recommendation-Project" version := "1.0" scalaVersion := "2.11.7" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.4.1" % "provided" libraryDependencies += "org.apache.spark" %% "spark-mllib" % "1.4.1" % "provided" libraryDependencies += "com.github.scopt" %% "scopt" % "3.3.0"
The keyword provided after spark-code and spark-mllib definitions excludes them from being bundled, since they are provided by the cluster manager at runtime. On the other hand, we don’t expect our target machine to include the scopt library, so we omit the provided keyword for this entry. Notice that provided keyword is parsed by the sbt-assembly plugin and used only in the creation of the final deployment jar.
We are now ready to create our dependencies for Eclipse:
~/RecommendationApp$ sbt eclipse
Picked up JAVA_TOOL_OPTIONS: -javaagent:/usr/share/java/jayatanaag.jar
[info] Loading global plugins from /home/osboxes/.sbt/0.13/plugins
[info] Set current project to Recommendation-Project (in build file:/home/osboxes/RecommendationApp/)
[info] About to create Eclipse project files for your project(s).
[info] Updating {file:/home/osboxes/RecommendationApp/}recommendationapp...
[info] Resolving jline#jline;2.12.1 ...
[info] Done updating.
[info] Successfully created Eclipse project files for project(s):
[info] Recommendation-Project
~/RecommendationApp$
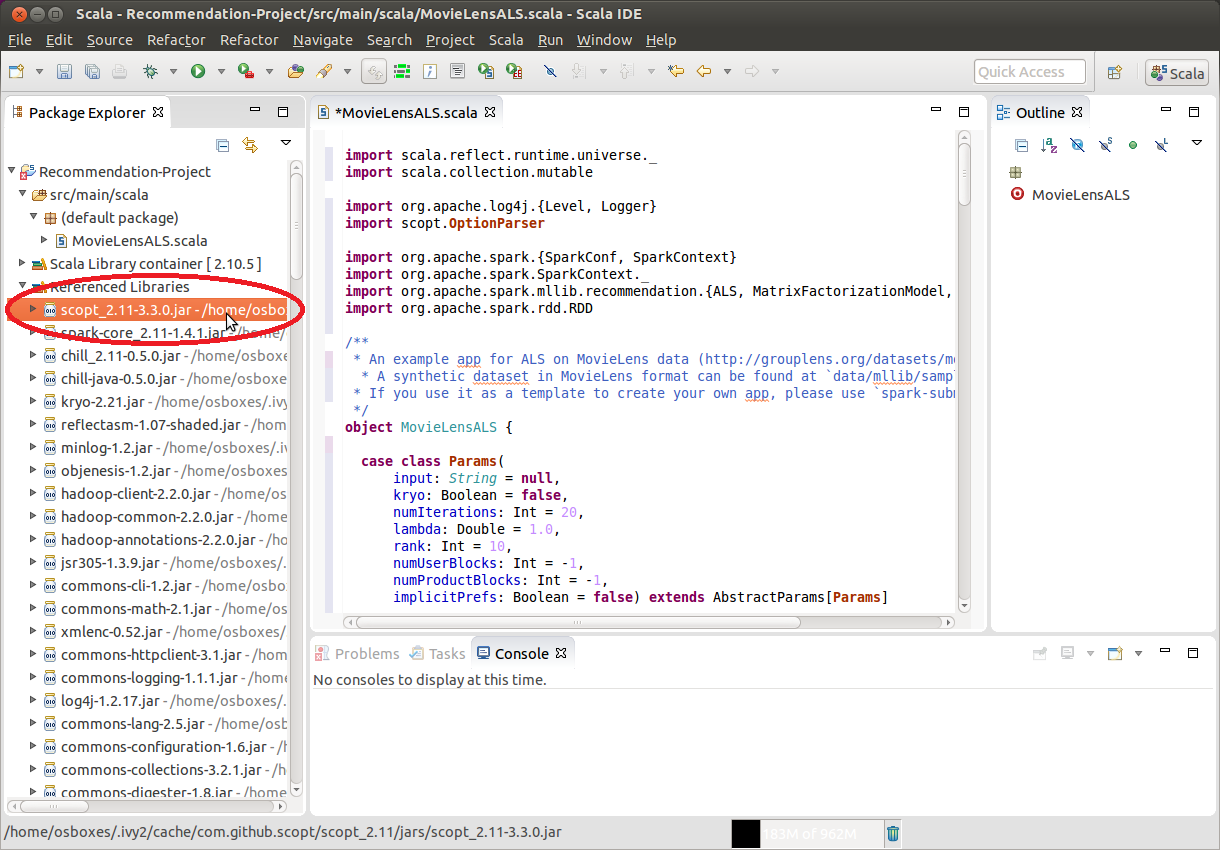
Refresh the project inside, Eclipse and verify that all dependencies are indeed resolved:
Assembly the new project
We can modify and expand further the source code using Eclipse. Suppose now we are ready to package it and deploy it as a standalone application; we need the sbt-assembly plugin that will include in the final jar all dependencies not marked as provided:
~/RecommendationApp$ sbt assembly Picked up JAVA_TOOL_OPTIONS: -javaagent:/usr/share/java/jayatanaag.jar [info] Loading global plugins from /home/osboxes/.sbt/0.13/plugins [info] Set current project to Recommendation-Project (in build file:/home/osboxes/RecommendationApp/) [info] Compiling 1 Scala source to /home/osboxes/RecommendationApp/target/scala-2.11/classes... [warn] there was one deprecation warning; re-run with -deprecation for details [warn] one warning found [info] Including: scopt_2.11-3.3.0.jar [info] Including: scala-library-2.11.7.jar [info] Checking every *.class/*.jar file's SHA-1. [info] Merging files... [warn] Merging 'META-INF/MANIFEST.MF' with strategy 'discard' [warn] Strategy 'discard' was applied to a file [info] SHA-1: a33168893fcac61a6540d6b48f53b02d604fd38c [info] Packaging /home/osboxes/RecommendationApp/target/scala-2.11/Recommendation-Project-assembly-1.0.jar ... [info] Done packaging. [success] Total time: 35 s, completed 31-Jul-2015 07:55:39
We can see that the scopt and scala libraries were included in the final jar for deployment. The jar package is called Recommendation-Project-assembly-1.0.jar. We can now deploy it using spark-submit, but first we need to download a valid ratings file of the form UserID::MovieID::Rating::Timestamp from the Movielens database – just use wget as shown below:
~$ wget http://files.grouplens.org/datasets/movielens/ml-1m.zip --2015-08-07 11:51:51-- http://files.grouplens.org/datasets/movielens/ml-1m.zip Resolving files.grouplens.org (files.grouplens.org)... 128.101.34.146 Connecting to files.grouplens.org (files.grouplens.org)|128.101.34.146|:80... connected. HTTP request sent, await</code>ing response... 200 OK Length: 5917392 (5.6M) [application/zip] Saving to: ‘ml-1m.zip’ ml-1m.zip 100%[=======================================>] 5.64M 338KB/s in 18s 2015-08-07 11:52:09 (327 KB/s) - ‘ml-1m.zip’ saved [5917392/5917392] ~$ unzip ml-1m.zip Archive: ml-1m.zip creating: ml-1m/ inflating: ml-1m/movies.dat inflating: ml-1m/ratings.dat inflating: ml-1m/README inflating: ml-1m/users.dat ~$ head ml-1m/ratings.dat 1::1193::5::978300760 1::661::3::978302109 1::914::3::978301968 1::3408::4::978300275 1::2355::5::978824291 1::1197::3::978302268 1::1287::5::978302039 1::2804::5::978300719 1::594::4::978302268 1::919::4::978301368
Now we can run spark-submit as follows:
~/RecommendationApp$ spark-submit --class "MovieLensALS" --master local[2] target/scala-2.11/Recommendation-Project-assembly-1.0.jar --rank 5 --lambda 0.1 ~/ml-1m/ratings.dat Picked up JAVA_TOOL_OPTIONS: -javaagent:/usr/share/java/jayatanaag.jar Picked up JAVA_TOOL_OPTIONS: -javaagent:/usr/share/java/jayatanaag.jar 15/07/31 08:01:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/07/31 08:01:48 WARN Utils: Your hostname, osboxes resolves to a loopback address: 127.0.1.1; using 10.0.2.15 instead (on interface eth0) 15/07/31 08:01:48 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address ... Got 1000209 ratings from 6040 users on 3706 movies. ... Training: 800197, test: 200012. ... [Stage 17:> (0 + 0) / 2]15/07/31 08:02:28 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS ... Test RMSE = 0.8737897446065059. ~/RecommendationApp$
rank and lambda are arguments that need to be provided to our program, which outputs a root mean squared error (RMSE) for the test set. Explanation of the detailed meanings of these parameters are beyond the scope of the present post.
Recap
As we mentioned also in our previous post, when working with external dependencies the development/deploy cycle goes like:
- Use Eclipse to modify the project and test it
- Use the
sbt assemblyto create the final jar - Deploy using
spark-submit - Go to step 1, if necessary, and refine further
In this post, we have demonstrated steps 1-3 above, this time with a realistic application involving moving recommendations, which required packaging also extra Spark and Scala libraries with our project.
- Nonlinear regression using Spark – Part 2: sum-of-squares objective functions - October 31, 2016
- How to evaluate R models in Azure Machine Learning Studio - August 24, 2016
- Nonlinear regression using Spark – Part 1: Nonlinear models - February 10, 2016
Great post.
Great Post!!
[…] Blog Development and deployment of Spark applications with Scala, Eclipse, and sbt – Part 1: Installation & configuration […]
I´ve tried this tutorial, but i get an error after submit. Have anybody an idea?
Thist ist the Stacktrace:
Exception in thread “main” java.lang.NoSuchMethodError: scala.reflect.api.JavaUniverse.runtimeMirror(Ljava/lang/ClassLoader;)Lscala/reflect/api/JavaUniverse$JavaMirror;
at MovieLensALS$Params.(MovieLensALS.scala:27)
at MovieLensALS$.main(MovieLensALS.scala:30)
at MovieLensALS.main(MovieLensALS.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:672)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Hello Thorsten,
It is crucial that you set the directory structure correctly.
./src
./src/main
./src/main/scala
Can you confirm that, so that I can start digging the issue deeper?
All the best,
Costas
Yes, this is the structure.
Different from the tutorial is that i build with sbt on my windows maschine, and my spark Cluster runs with Spark 1.5.0
The previous tut works fine.
Ok, is fixed it.
It seems so that Spark 1.5.0 is build with Scala 2.10. I chaged the recommendation.sbt the scalaVersion to 2.10.4 and everything works fine, strange.
Did you use a Spark version build with Scala 2.11 ?
Great! I am happy you have resolved your issue!
I have compiled Spark 1.4.1 using Scala 2.11. I believe that
many precompiled versions still use Scala 2.10.
Thank you,
Costas
Indeed, before Spark 2.0, all pre-built binaries were built with Scala 2.10.
Hi Constantinos,
Thankyou for the great post. This allowed me to break shackles on how to execute a spark application. Can you assist me in deploying this application in a Two Node HDFS cluster running YARN. Any help is greatly appreciated.
[…] the code from here. You can use the sbt utility to create an eclipse project like described in this post. Then import the project in eclipse and run the SumOfSquareTest.scala file as a Scala application. […]